
Computer-use agents have been limited to primitives. They click, they type, they scroll. Long action chains amplify grounding errors and waste steps. Apple Researchers introduce UltraCUA, a foundation model that builds an hybrid action space that lets an agent interleave low level GUI actions with high level programmatic tool calls. The model chooses the cheaper and more reliable move at each step. The approach improves success and reduces steps on OSWorld, and transfers to WindowsAgentArena without Windows specific training.
What hybrid action changes?
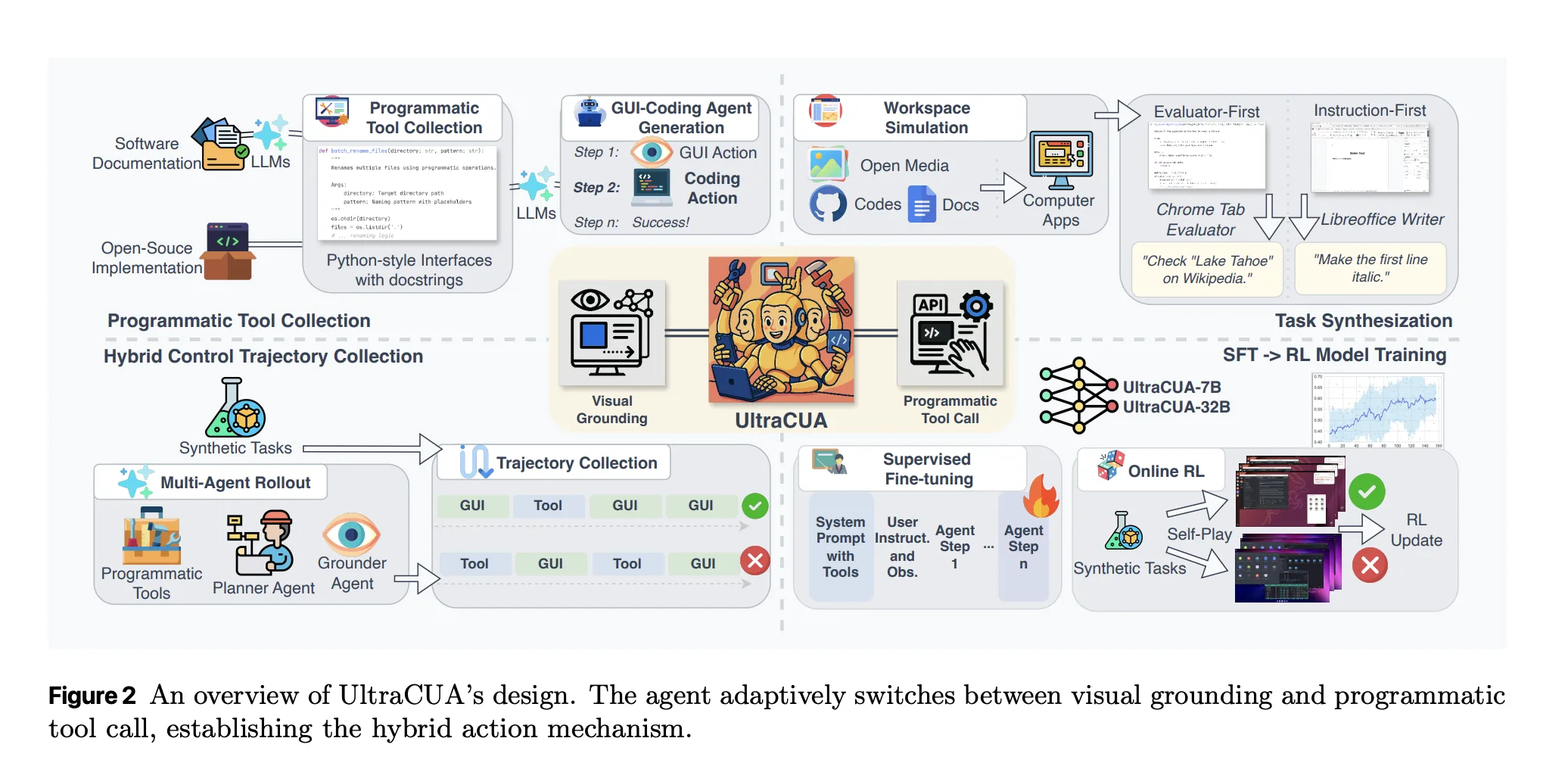
Hybrid action treats tools as first class actions. A tool call encapsulates a multi step operation as a single function with a clear signature and a docstring. A click or a key press still exists when no programmatic path is available. The agent learns to alternate between both modes. The goal is to reduce cascade errors and to cut step counts. The research team positions this as a bridge between GUI only CUAs and tool centric agent frameworks.
Scaled tool acquisition
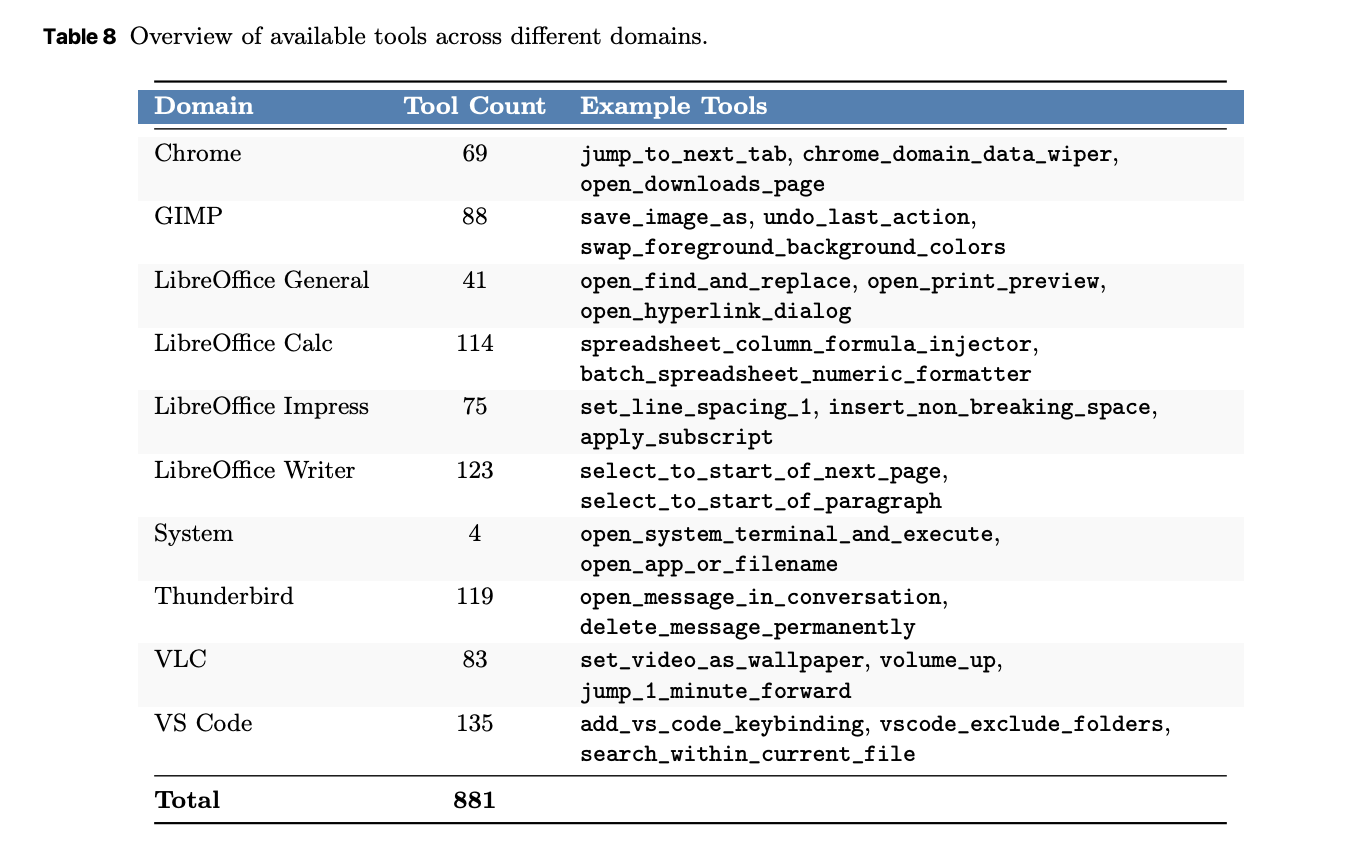
UltraCUA builds its tool library with an automated pipeline. The system extracts keyboard shortcuts and commands from software documentation. The system integrates open source implementations from agent toolkits. The system also uses coding agents to synthesize new tools. Each tool is a callable interface that hides a long GUI sequence. The research team reports coverage across 10 desktop domains with 881 tools. The largest buckets include VS Code with 135 tools and LibreOffice Writer with 123 tools. Thunderbird and GIMP also have deep coverage.
Verifiable synthetic tasks and trajectories
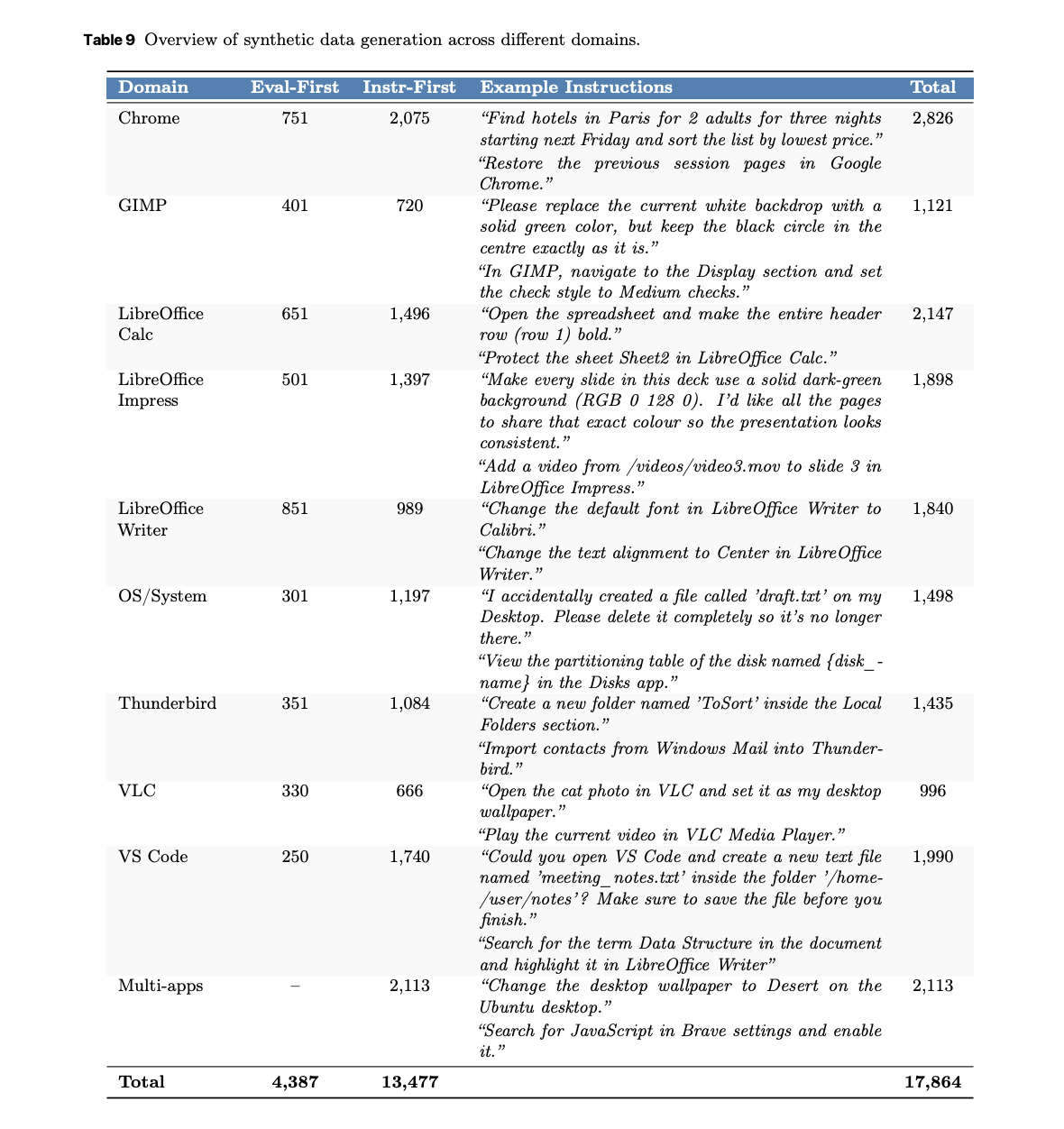
Training requires grounded supervision and stable rewards. UltraCUA uses a dual synthetic engine. An evaluator first pipeline composes atomic verifiers for browsers, files, images, and system state, then generates tasks that satisfy those checks. An instruction first pipeline explores the OS and proposes context aligned tasks which are then verified. The result is 17,864 verifiable tasks across 10 domains such as Chrome, LibreOffice, GIMP, VS Code, system, Thunderbird, VLC, and multi app workflows. Chrome has 2,826 tasks. The LibreOffice suite sums to 5,885 tasks. Multi app tasks reach 2,113.
A multi agent rollout produces successful hybrid trajectories. The planner uses OpenAI o3 for decision making. The grounder uses GTA1-7B for accurate visual localization. The rollout yields about 26.8K successful trajectories that show when to use a tool and when to act in the GUI. These trajectories are the core of the supervised phase.
Training Approach
Training has two stages. Stage 1 is supervised fine tuning. The models train for 3 epochs at a learning rate of 2e-5 on the successful trajectories. Loss is applied turn wise to avoid over weighting early steps. Stage 2 is online reinforcement learning. The models train for 150 steps at a learning rate of 1e-6 on verified tasks that are sampled by difficulty. The policy optimization follows a GRPO variant with clip higher, and removes KL regularization and format rewards. The reward combines sparse task outcome with a tool use term. Experiments use NVIDIA H100 GPUs. The context is kept near 32K by controlling the number of exposed tools.
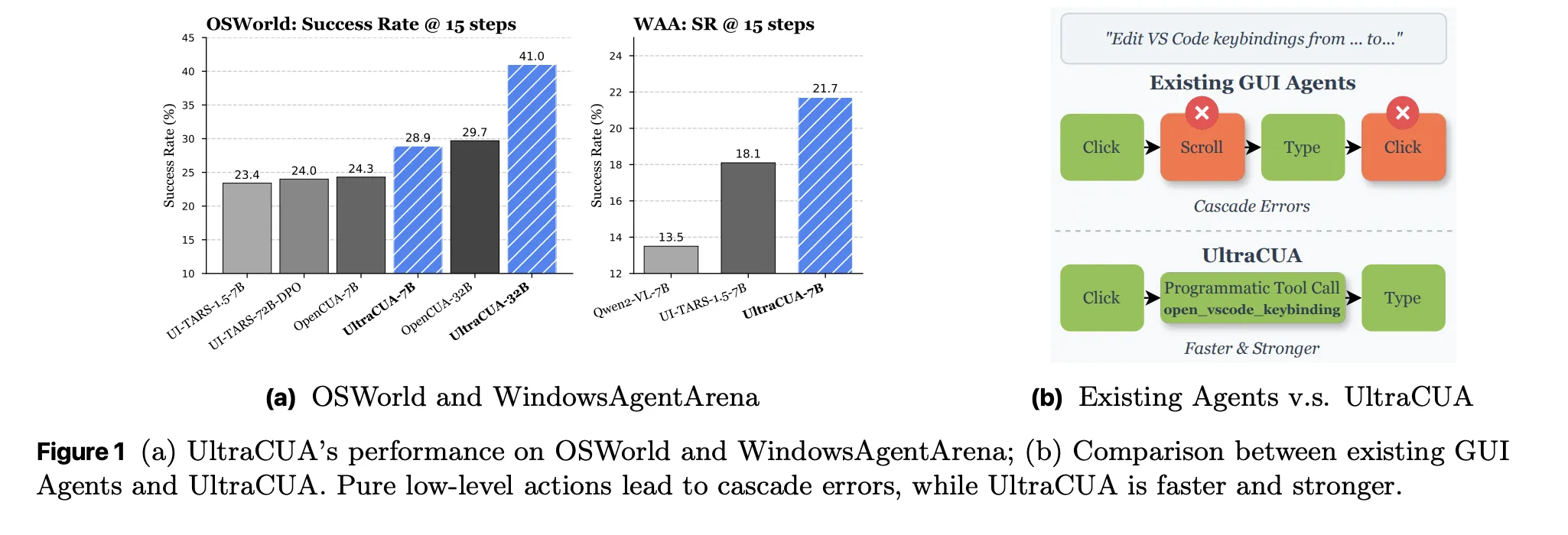
Results on OSWorld
UltraCUA improves success at both 7B and 32B scales. Under 15 step budgets, UltraCUA-32B reaches 41.0 percent success. OpenCUA-32B reaches 29.7 percent. The absolute gain is 11.3 points. UltraCUA-7B reaches 28.9 percent. UI-TARS-1.5-7B reaches 23.4 percent. Gains persist under 50 step budgets. A per domain breakdown shows consistent lifts across Chrome, Writer, VS Code, and cross application tasks. Average steps decrease against baselines. These shifts indicate better action selection rather than only more attempts.
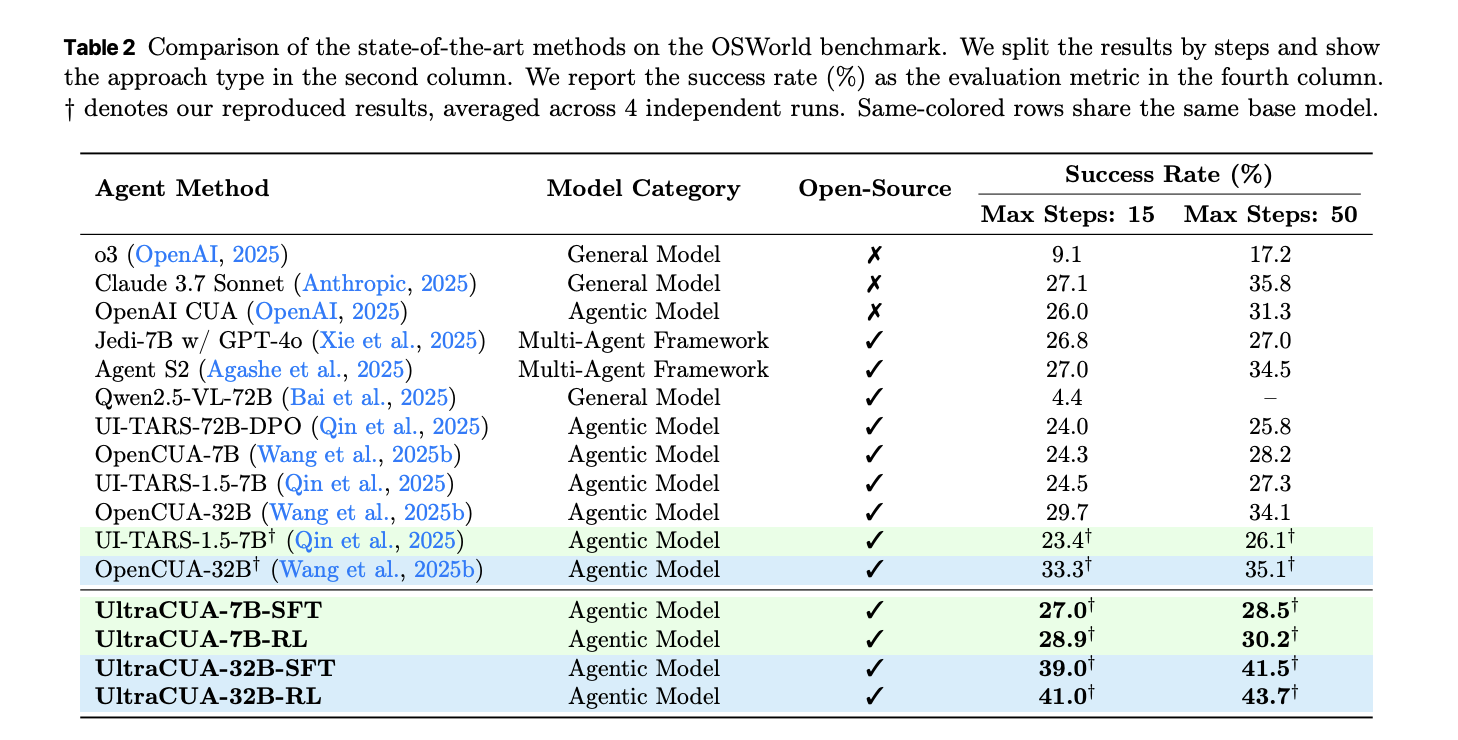
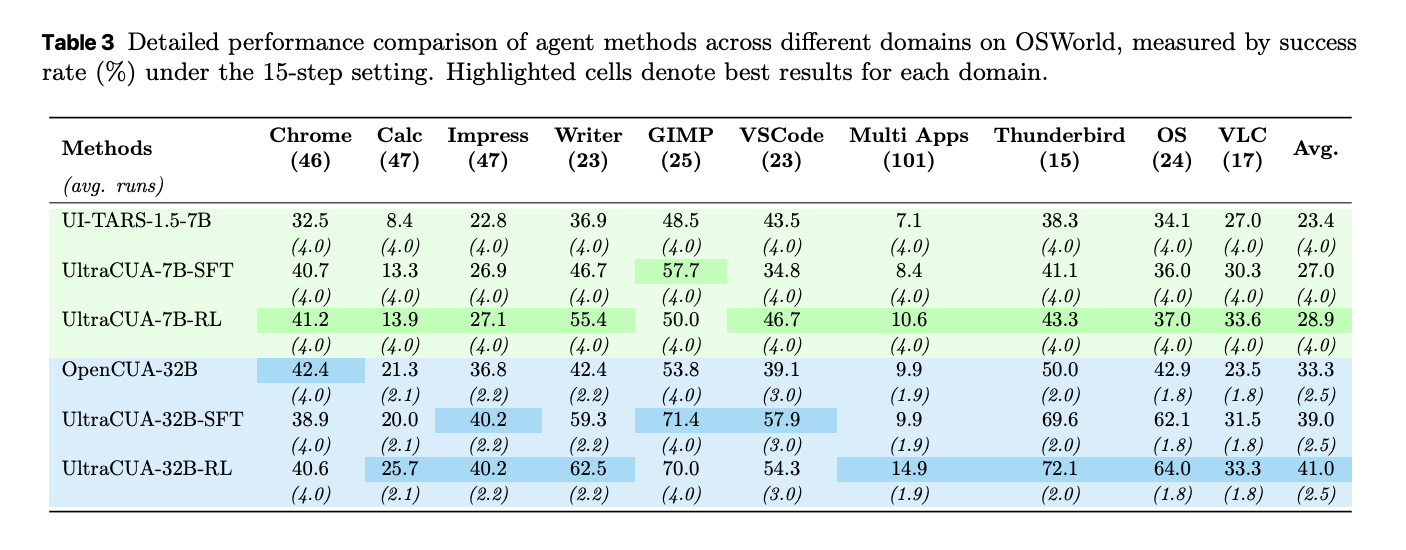
Cross platform transfer on WindowsAgentArena
UltraCUA trains only on Ubuntu based OSWorld data. The model is then evaluated on WindowsAgentArena. UltraCUA-7B reaches 21.7 percent success. This exceeds UI-TARS-1.5-7B at 18.1 percent and a Qwen2 baseline trained with Windows data at 13.5 percent. The result suggests that hybrid action strategies learned on one platform transfer to other platforms. The paper highlights this as zero shot platform generalization.

Key Takeaways
- UltraCUA formalizes a hybrid action space that lets a single agent alternate between GUI primitives and programmatic tool calls, which reduces long error prone action chains.
- The research team scales a reusable tool library through an automated pipeline and pairs it with a synthetic data engine, yielding 17,000 plus verifiable computer use tasks for training and evaluation.
- Training follows a two stage recipe, supervised fine tuning on successful hybrid trajectories then online reinforcement learning on verifiable tasks, which optimizes when to call tools versus act in the GUI.
- On OSWorld, UltraCUA reports an average 22 percent relative improvement over base models and 11 percent fewer steps, which indicates gains in reliability and efficiency.
- The 7B model reaches 21.7 percent success on WindowsAgentArena without Windows specific training, which shows cross platform generalization of the hybrid action policy.
UltraCUA moves computer use agents from brittle primitive action chains to a hybrid action policy, integrating GUI primitives with programmatic tool calls, which reduces error propagation and step counts. It scales tools via an automated pipeline and pairs them with a synthetic data engine that yields 17,000 plus verifiable tasks, enabling supervised fine tuning and online reinforcement learning on grounded signals. Reported results include 22 percent relative improvement on OSWorld with 11 percent fewer steps, and 21.7 percent success on WindowsAgentArena without Windows specific training, which indicates cross platform transfer of the policy.
Check out the Paper here. Feel free to check out our GitHub Page for Tutorials, Codes and Notebooks. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.

Michal Sutter is a data science professional with a Master of Science in Data Science from the University of Padova. With a solid foundation in statistical analysis, machine learning, and data engineering, Michal excels at transforming complex datasets into actionable insights.


