
Anthropic recently released a guide on effective Context Engineering for AI Agents — a reminder that context is a critical yet limited resource. The quality of an agent often depends less on the model itself and more on how its context is structured and managed. Even a weaker LLM can perform well with the right context, but no state-of-the-art model can compensate for a poor one.
Production-grade AI systems need more than good prompts — they need structure: a complete ecosystem of context that shapes reasoning, memory, and decision-making. Modern agent architectures now treat context not as a line in a prompt, but as a core design layer.
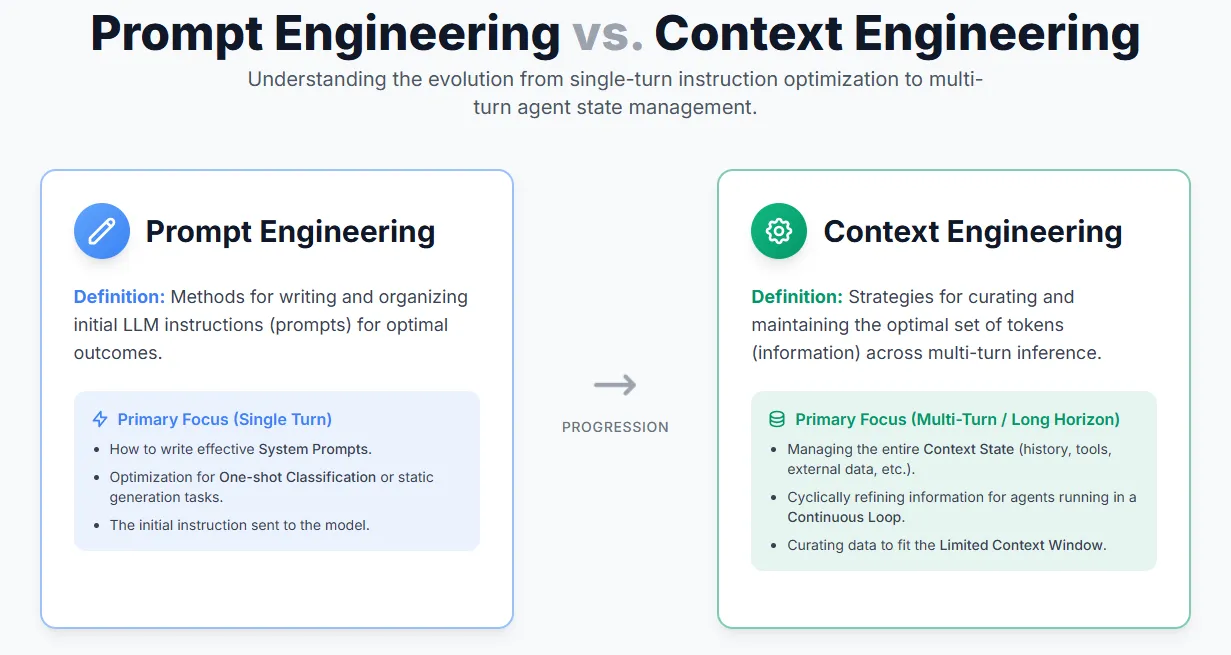
Difference between Context Engineering & Prompt Engineering
Prompt engineering focuses on crafting effective instructions to guide an LLM’s behavior — essentially, how to write and structure prompts for the best output.
Context engineering, on the other hand, goes beyond prompts. It’s about managing the entire set of information the model sees during inference — including system messages, tool outputs, memory, external data, and message history. As AI agents evolve to handle multi-turn reasoning and longer tasks, context engineering becomes the key discipline for curating and maintaining what truly matters within the model’s limited context window.
Why is Context Engineering Important?
LLMs, like humans, have limited attention — the more information they’re given, the harder it becomes for them to stay focused and recall details accurately. This phenomenon, known as context rot, means that simply increasing the context window doesn’t guarantee better performance.

Because LLMs operate on the transformer architecture, every token must “attend” to every other token, which quickly strains their attention as context grows. As a result, long contexts can cause reduced precision and weaker long-range reasoning.
That’s why context engineering is crucial: it ensures that only the most relevant and useful information is included in an agent’s limited context, allowing it to reason effectively and stay focused even in complex, multi-turn tasks.
What Makes Context Effective?
Good context engineering means fitting the right information—not the most—into the model’s limited attention window. The goal is to maximize useful signal while minimizing noise.
Here’s how to design effective context across its key components:
System Prompts
- Keep them clear, specific, and minimal — enough to define desired behavior, but not so rigid they break easily.
- Avoid two extremes:
- Overly complex, hardcoded logic (too brittle)
- Vague, high-level instructions (too broad)
- Use structured sections (like ,
, ## Output format) to improve readability and modularity. - Start with a minimal version and iterate based on test results.
Tools
- Tools act as the agent’s interface to its environment.
- Build small, distinct, and efficient tools — avoid bloated or overlapping functionality.
- Ensure input parameters are clear, descriptive, and unambiguous.
- Fewer, well-designed tools lead to more reliable agent behavior and easier maintenance.
Examples (Few-Shot Prompts)
- Use diverse, representative examples, not exhaustive lists.
- Focus on showing patterns, not explaining every rule.
- Include both good and bad examples to clarify behavior boundaries.
Knowledge
- Feed domain-specific information — APIs, workflows, data models, etc.
- Helps the model move from text prediction to decision-making.
Memory
- Gives the agent continuity and awareness of past actions.
- Short-term memory: reasoning steps, chat history
- Long-term memory: company data, user preferences, learned facts
Tool Results
- Feed tool outputs back into the model for self-correction and dynamic reasoning.

Context Engineering Agent Workflow
Dynamic Context Retrieval (The “Just-in-Time” Shift)
- JIT Strategy: Agents transition from static, pre-loaded data (traditional RAG) to autonomous, dynamic context management.
- Runtime Fetching: Agents use tools (e.g., file paths, queries, APIs) to retrieve only the most relevant data at the exact moment it’s needed for reasoning.
- Efficiency and Cognition: This approach drastically improves memory efficiency and flexibility, mirroring how humans use external organization systems (like file systems and bookmarks).
- Hybrid Retrieval: Sophisticated systems, like Claude Code, employ a hybrid strategy, combining JIT dynamic retrieval with pre-loaded static data for optimal speed and versatility.
- Engineering Challenge: This requires careful tool design and thoughtful engineering to prevent agents from misusing tools, chasing dead-ends, or wasting context.
Long-Horizon Context Maintenance
These techniques are essential for maintaining coherence and goal-directed behavior in tasks that span extended periods and exceed the LLM’s limited context window.
Compaction (The Distiller):
- Preserves conversational flow and critical details when the context buffer is full.
- Summarizes old message history and restarts the context, often discarding redundant data like old raw tool results.
Structured Note-Taking (External Memory):
- Provides persistent memory with minimal context overhead.
- The agent autonomously writes persistent external notes (e.g., to a NOTES.md file or a dedicated memory tool) to track progress, dependencies, and strategic plans.
Sub-Agent Architectures (The Specialized Team):
- Handles complex, deep exploration tasks without polluting the main agent’s working memory.
- Specialized sub-agents perform deep work using isolated context windows, then return only a condensed, distilled summary (e.g., 1-2k tokens) to the main coordinating agent.

I am a Civil Engineering Graduate (2022) from Jamia Millia Islamia, New Delhi, and I have a keen interest in Data Science, especially Neural Networks and their application in various areas.


