
Embedding models act as bridges between different data modalities by encoding diverse multimodal information into a shared dense representation space. There have been advancements in embedding models in recent years, driven by progress in large foundation models. However, existing multimodal embedding models are trained on datasets such as MMEB and M-BEIR, with most focus only on natural images and photographs sourced from the MSCOCO, Flickr, and ImageNet datasets. These datasets fail to cover larger forms of visual information, including documents, PDFs, websites, videos, and slides. This causes existing embedding models to underperform on realistic tasks such as article searching, website searching, and YouTube video search.
Multimodal embedding benchmarks such as MSCOCO, Flickr30K, and Conceptual Captions initially focused on static image-text pairs for tasks like image captioning and retrieval. More recent benchmarks, such as M-BEIR and MMEB, introduced multi-task evaluations, but remain limited to static images and short contexts. Video representation learning has evolved through models like VideoCLIP and VideoCoCa, integrating contrastive learning with captioning objectives. Visual document representation learning advanced through models like ColPali and VisRAG, which use VLMs for document retrieval. Unified modality retrieval methods like GME and Uni-Retrieval achieve strong performance on universal benchmarks. However, none can unify image, video, and visual document retrieval within a single framework.
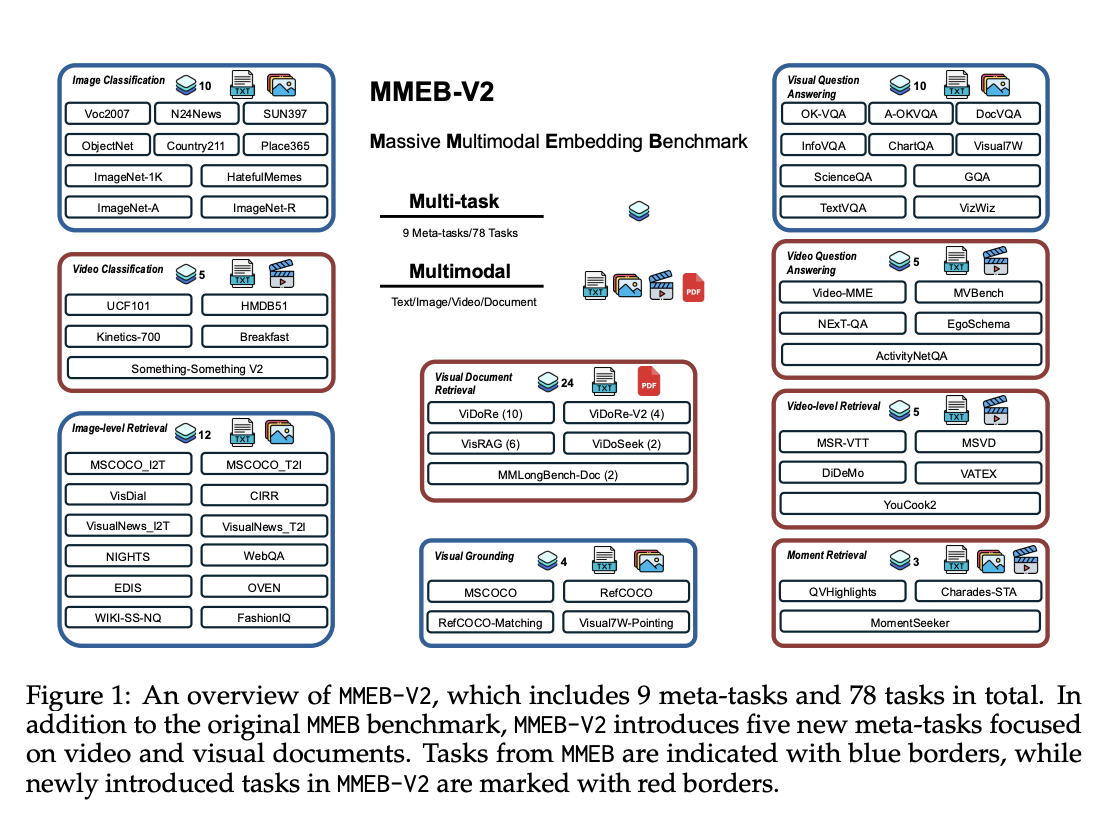
Researchers from Salesforce Research, UC Santa Barbara, University of Waterloo, and Tsinghua University have proposed VLM2Vec-V2 to unify image, video, and visual document retrieval within a single framework. Firstly, researchers developed MMEB-V2, a benchmark that extends MMEB with five new task types, including visual document retrieval, video retrieval, temporal grounding, video classification, and video question answering. Secondly, VLM2Vec-V2 serves as a general-purpose embedding model that supports multiple input modalities while demonstrating strong performance on both newly introduced tasks and original image benchmarks. This establishes a foundation for more scalable and flexible representation learning in both research and practical applications.
VLM2Vec-V2 utilizes Qwen2-VL as its backbone, selected for its specialized capabilities in multimodal processing. Qwen2-VL offers three critical features that support unified embedding learning: Naive Dynamic Resolution, Multimodal Rotary Position Embedding (M-RoPE), and a unified framework that combines 2D and 3D convolutions. To enable effective multi-task training across diverse data sources, VLM2Vec-V2 introduces a flexible data sampling pipeline with two key components: (a) on-the-fly batch mixing based on predefined sampling weight tables that control the relative probabilities of each dataset, and (b) an interleaved sub-batching strategy that splits full batches into independently sampled sub-batches, improving the stability of contrastive learning.
VLM2Vec-V2 achieves the highest overall average score of 58.0 across 78 datasets covering image, video, and visual document tasks, outperforming strong baselines including GME, LamRA, and VLM2Vec built on the same Qwen2-VL backbone. On image tasks, VLM2Vec-V2 outperforms most baselines by significant margins and achieves performance comparable to VLM2Vec-7B despite being only 2B parameters in size. For video tasks, the model achieves competitive performance despite training on relatively small amounts of video data. In visual document retrieval, VLM2Vec-V2 outperforms all VLM2Vec variants, but still lags behind ColPali, which is specifically optimized for visual document tasks.
In conclusion, researchers introduced VLM2Vec-V2, a strong baseline model trained through contrastive learning across diverse tasks and modality combinations. VLM2Vec-V2 is built upon MMEB-V2 and uses Qwen2-VL as its backbone model. MMEB-V2 is a benchmark designed by researchers to assess multimodal embedding models across various modalities, including text, images, videos, and visual documents. The experimental evaluation demonstrates the effectiveness of VLM2Vec-V2 in achieving balanced performance across multiple modalities while highlighting the diagnostic value of MMEB-V2 for future research.
Check out the Paper, GitHub Page and Model on Hugging Face. All credit for this research goes to the researchers of this project. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter.

Sajjad Ansari is a final year undergraduate from IIT Kharagpur. As a Tech enthusiast, he delves into the practical applications of AI with a focus on understanding the impact of AI technologies and their real-world implications. He aims to articulate complex AI concepts in a clear and accessible manner.



